原作:jasonwei,
引言:如今,一个悬而未决的问题是,为什么大型语言模型如此有效。在这篇博文中,我将讨论有关大型语言模型的六个基本直觉。其中许多直觉受到手动检查数据的启发,这是一项我发现有帮助且会推荐的练习。
语言模型经过预训练,可以简单地预测文本语料库中的下一个单词,并且它们由此学到了惊人的知识。让我们看一些示例,了解它们可能从这个下一个单词预测任务中学到什么。
直觉 1. 对大型自监督数据进行下一个单词预测是大规模多任务学习。
尽管下一个单词预测是一项极其简单的任务,但当与海量数据集结合使用时,它会迫使模型学习大量任务。考虑以下传统 NLP 任务示例,这些任务可以通过预测语料库中某些文本的下一个单词来学习。
| 前缀 {choice_1, choice_2} | 任务 |
|---|---|
| 在空闲时间,我喜欢 {跑步,香蕉} | 语法 |
| 我去动物园看长颈鹿、狮子和{斑马、勺子} | 词法语义 |
| 丹麦的首都{哥本哈根、伦敦} | 世界知识 |
| 我整场都在笑,这部电影{好、坏} | 情感分析 |
| 西班牙语中“漂亮”一词是{bonita、hola} | 翻译 |
| 一年级算术考试:3 + 8 + 4 = {15、11} | 数学问题 |
上述任务明确无误,但有点理想化。实际上,预测下一个单词涉及执行许多“奇怪”的任务。考虑以下句子:
| 前缀 | 下一个单词 [任务] |
|---|---|
| Transformer 是一种深度学习架构,最初在 | 2017 年提出 [事实回忆] |
| Transformer 是一种深度学习架构,最初在 2017 年提出 | ,[逗号预测] |
| Transformer 是一种深度学习架构,最初在 2017 年提出, | 即 [语法] |
| Transformer 是一种深度学习架构,最初在 2017 年提出,即 | 依赖 [不可能的任务?] |
当您以这种方式查看数据时,很明显,下一个单词预测迫使模型学习很多关于语言的知识;不仅是语法和语义,还有逗号预测、事实知识,甚至可能是推理等内容。这是一个有趣的例子,说明了一个简单的目标如何与复杂的数据相结合,从而产生高度智能的行为(假设您同意语言模型是智能的)。
直觉 2. 学习输入输出关系可以转化为下一个单词预测。这被称为上下文学习(情景学习)。
过去几十年的机器学习专注于学习<input, output>对之间的关系。由于下一个单词预测非常通用,我们可以轻松地将机器学习转化为下一个单词预测。我们称之为上下文学习(又称情景学习,少样本学习或少样本提示)。这是由 GPT-3 论文开创的,该论文提出了使用自然语言指令,然后是<input, output>对。这在 GPT-3 论文的以下左图中显示。
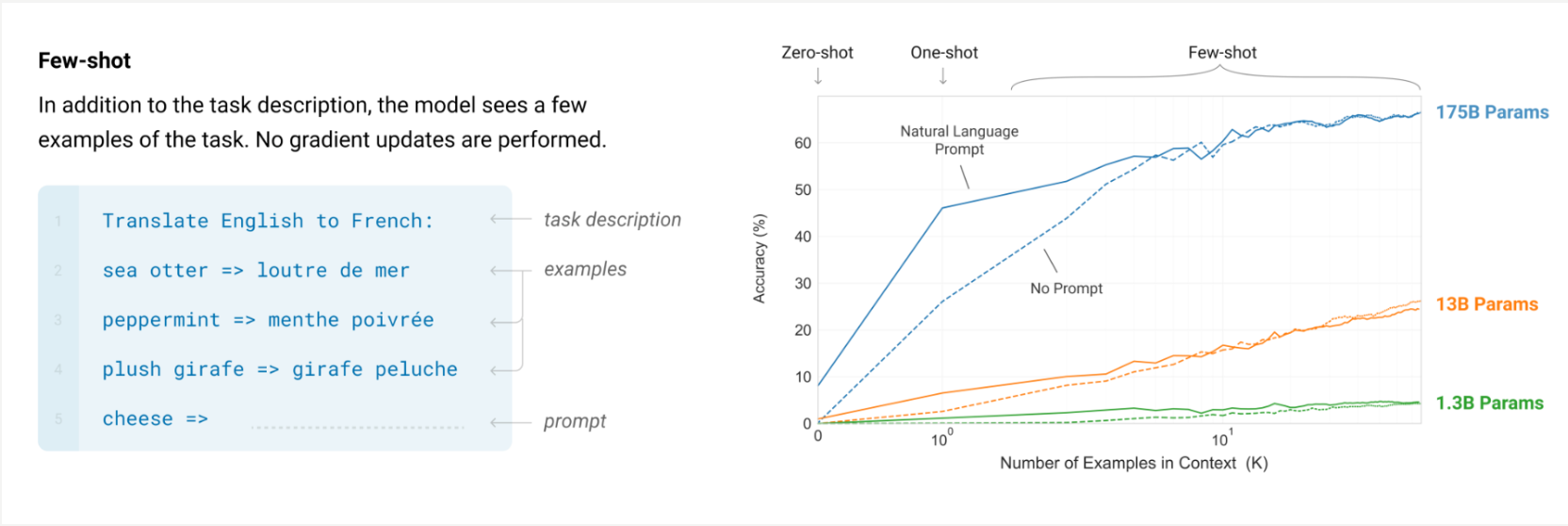
在上方图片的右侧,我们可以看到,增加上下文中的示例数量可以提高 GPT-3 论文中任务的性能。这意味着该模型受益于查看这些 <input, output> 示例。
上下文学习是大语言模型的一种标准表述,很方便,因为 <input, output> 对是我们过去几十年来进行机器学习的方式。但是,我们继续遵循<input, output>对并没有第一性原理的理由。当我们与人类交流时,我们也会给他们指示、解释并以交互方式引导他们。
直觉 3. Token 的信息密度可能非常不同,因此要给语言模型时间来思考。
一个基本的事实是,并非所有token在信息方面都是等值的。
有些token非常容易猜测,但没有太大价值。例如,在“我是 OpenAI 的研究员 Jason Wei,从事大型语言 ___ 的工作”中,预测“模型”并不难。预测该标记非常容易,以至于如果我省略它,也不会丢失太多信息。
有些token很难猜测;但很有价值。例如,在“Jason Wei 最喜欢的颜色是 ___”中,几乎不可能预测。因此,该标记包含大量新信息。
有些token也可能很难计算。例如,在“问题:((8-2)*3+4)^3/8 的平方是多少?(A)1,483,492;(B)1,395,394;(C)1,771,561;答案:()中,下一个标记需要大量工作(计算该表达式)。
你可以想象,如果你是 ChatGPT,并且一旦你必须看到 prompt,你必须立即开始输入,那么正确回答这个问题将非常困难。
/这有点类似快思考、慢思考/
解决办法是通过允许语言模型在给出最终答案之前执行自然语言推理,从而为语言模型提供更多计算能力。这可以通过一种称为“思维链提示”的简单技巧来完成,该技巧通过在少数镜头示例中提供“思维链”的示例(以蓝色突出显示)来鼓励模型进行推理。
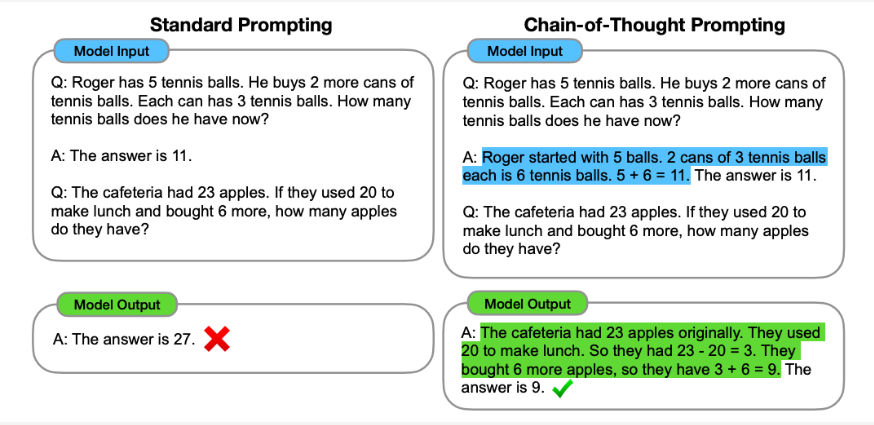
这种技术对于提高复杂推理任务的性能非常有用,这些任务需要人类花费一秒钟以上的时间来解决。对于比上面所示的简单算术问题更复杂的问题,让语言模型先将prompt分解成子问题,然后顺序解决子问题(“从最少到最多提示”)会有所帮助。这种范例非常强大,因为我们希望人工智能最终能够解决我们人类面临的最困难的问题(例如,贫困、气候变化等),而推理能力是解决此类问题的基础。
上述下一个单词预测任务之所以有效,关键原因在于扩展(scaling),这意味着需要在更多数据上训练更大的神经网络。显然,训练前沿语言模型需要花费大量资金,因此我们这样做的原因是我们有合理的信心,使用更大的神经网络和更多数据实际上将导致更好的模型(即,当您增加模型和数据时,性能可能不会饱和)。
直觉 4. 扩展语言模型(大小和数据)预计将继续改善损失。
扩展可以提高可预测的性能这一事实被称为“扩展定律(scaling laws)”,下图左侧显示,随着计算的增加,测试损失会平稳改善。
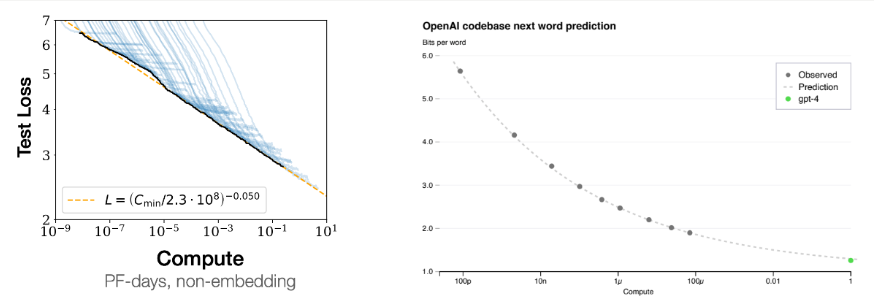
右图是另一个证据,说明随着语言模型的扩展,损失如何平稳地得到改善——通过追踪较小模型的损失曲线,你可以使用少至 10,000 倍的计算来预测 GPT-4 的损失。
为什么扩展(scaling )有效是一个开放性问题,但这里有两个似是而非的原因。一个原因是小型语言模型无法在其参数中记忆太多知识,而大型语言模型可以记忆大量关于世界的事实信息。第二个猜测是,虽然小型语言模型受容量限制,但它们可能只学习数据中的一阶相关性。另一方面,大型语言模型可以在数据中学习复杂的启发式方法。
直觉 5. 虽然总体损失平稳扩展,但个别下游任务可能以新兴方式扩展(scale)。
让我们仔细看看当损失改善时究竟发生了什么。你可以将整体损失视为大量学习任务的加权平均值,例如,
整体损失 = 1e-10 *(语法任务的损失)+ 1e-10 * 损失(情感分析任务的损失)+ …
+ 1e-10 * (数学能力丧失任务)+ …
Overall loss = 1e-10 * (loss of grammar task) + 1e-10 * loss (loss of sentiment analysis task) + …
+ 1e-10 * (loss of math ability task) + …
现在考虑你的损失从 4 到 3 的变化。所有任务都会得到均匀的提高吗?可能不会。也许损失 = 4 的模型的语法已经很完美了,因此已经饱和,但损失 = 3 的模型的数学能力提高了很多。
事实证明,如果你查看模型在 200 个下游任务上的表现,你会看到,虽然有些任务平稳地提高,但其他任务根本没有提高,还有一些任务突然提高。以下是此类任务的八个示例,其中对于小型模型,性能几乎是随机的,而一旦模型大小达到某个阈值,性能就会增加到远高于随机水平。
我们用来表示由量变产生的质变的术语是“涌现(emergence)”。更具体地说,如果一种大型语言模型的能力在较小的模型中不存在,但在较大的模型中存在,那么我们称这种能力为涌现能力。在此类任务中,我们经常看到,对于较小的模型,其性能大都是随机的,而对于大于某个阈值大小的模型,其性能明显高于随机,如下图所示。
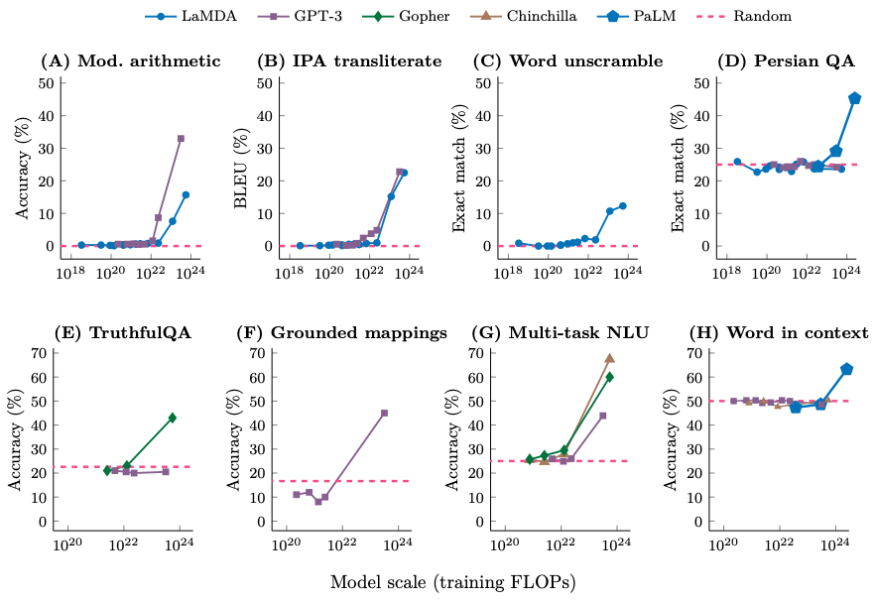
涌现具有三个重要的含义:
仅仅通过推断较小模型的缩放曲线,无法预测涌现。
语言模型的训练者并未明确指定涌现能力。
由于扩展已解锁涌现能力,因此可以预期进一步扩展将进一步引发更多能力。
直觉 6. 真正的情境学习(上下文学习)会发生,但只发生在足够大的语言模型中。
我们从 GPT-3 论文中看到,增加上下文示例的数量可以提高性能。虽然我们希望这是因为该模型实际上从其上下文中的示例中学习了<input, output>映射,但性能的提高可能是由于其他原因,例如示例告诉模型有关格式或可能的标签的信息。
事实上,一篇论文表明,即使您对上下文中的示例使用随机标签,GPT-3 的性能也几乎不会下降。他们认为,性能的提高不是由于学习<input, output>映射,而是由于上下文中的示例教授了诸如格式或可能的标签之类的东西。
然而,与当今最强大的模型相比,GPT-3 并不是一个超级“大型”语言模型。如果我们采用更极端的翻转标签设置(即,正面表示负面,负面表示正面),那么我们发现大型语言模型强烈遵循翻转标签,而小型语言模型根本不受性能影响。下图显示了这一点,其中大型语言模型(PaLM-540B、code-davinci-002 和 text-davinci-002)的性能下降。
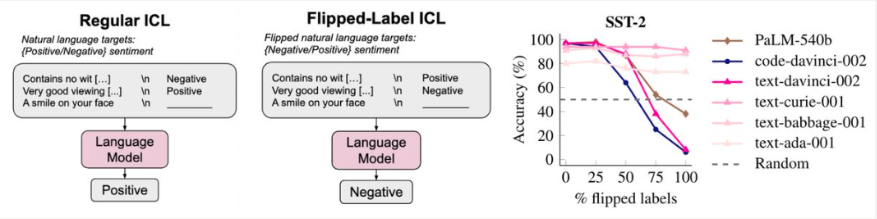
这里的要点是,语言模型确实会查看<input, output>映射,但前提是语言模型足够大。
尽管以上直觉非常基础,但我希望它们是有用的。许多直觉中都有一个共同的主题,那就是你可以通过手动查看数据学到很多东西。我最近很喜欢这样做,并强烈推荐 :)
